LightGBM 是由微軟公司於2017年四月釋出的一款基於決策樹(Decision Tree)學習算法的梯度提升框架。 Next, LightGBM is a gradient boosting framework that uses tree based learning algorithms. It is designed to be distributed and efficient with the following advantages:
其中, 決策樹是機器學習演算法中很重要的一環。在 Kaggle 的比賽中,有超過一半的勝利者都使用XGBoost。最近微軟發布了 Gradient Boosting 的框架 LightGBM ; 很多 Kaggle 的參賽者都開始使用 LightGBM 多於XGBoost 雖然 XGBoost 有更高的準確率,但是 LightGBM 比 XGBoost 運算的速度快10倍(以前), 目前則是快6倍。
Light = light weight
G = gradient
B = boosting
M = machines
Gradient boosting machines build sequential decision trees. Each tree will be built based on the previous tree’s error. Finally, predictions will be made by the sum of all of those trees.
XGBoost applies level-wise tree growth whereas LightGBM applies leaf-wise tree growth. This makes LightGBM faster. (Digram as below)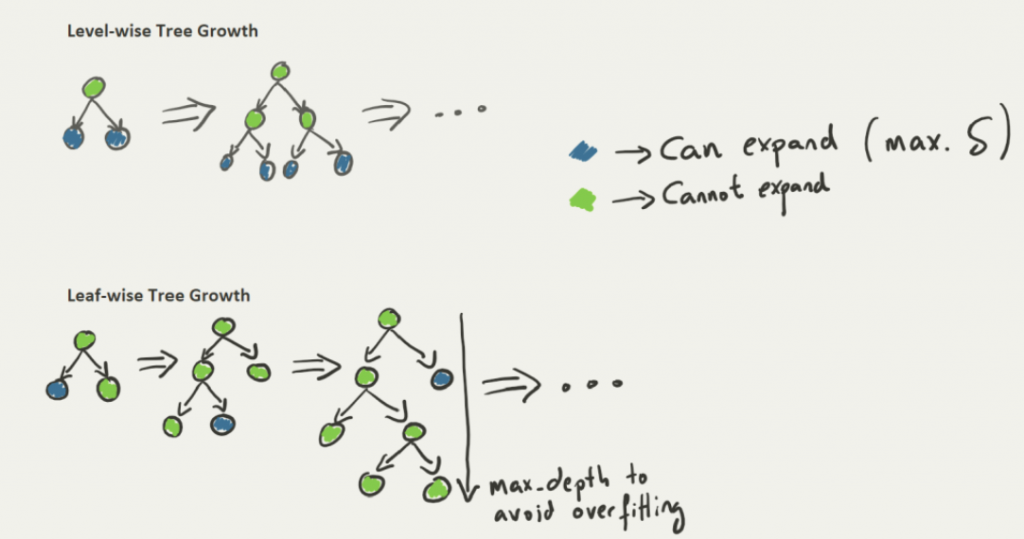
(LightGBM 完整參數可以參考: https://lightgbm.readthedocs.io/en/latest/Parameters.html)
首先 Download & install Pycharm ~ and create a "Project" (folder) for this project in Pycharm (with python env.)
此專案使用的資料為美國年薪高於 50K 的工作者所收集的data, 其data是參考 Kaggle 的dataset, 再加以ETL, 為 此專案實作使用的dataset; 此篇實作就以清洗後的dataset為範例~
Install those packages in Pycharm terminal
pip install --upgrade pip
pip install pandas
pip install numpy
pip install -U scikit-learn scipy matplotlib
pip install lightgbm
pip install scikit-multilearn
pip install flask_sqlalchemy
pip install termplotlib
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from skmultilearn.problem_transform import ClassifierChain
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score,multilabel_confusion_matrix
import sklearn.metrics as metrics
from sqlalchemy import create_engine
import lightgbm as lgb
from lightgbm import LGBMClassifier
from sklearn.multiclass import OneVsRestClassifier
import termplotlib as tpl
df_1 = pd.read_csv('usa_inc.csv')
df_1= pd.DataFrame(df_1)
print(df_1)
#Label encoding -> occupation, gender
from sklearn.preprocessing import LabelEncoder
labelencoder = LabelEncoder()
df_1['occupation'] = labelencoder.fit_transform(df_1['occupation'])
df_1['gender'] = labelencoder.fit_transform(df_1['gender'])
df_1.dropna()
#print(df_1)
You can try to print out the result, during the programing.
##get train and test data
X = df_1.iloc[:,2:4]
Y = df_1.iloc[:,0:1]
Y_2 = df_1.iloc[:,1:2]
train_x,test_x,train_y,test_y = train_test_split(X,Y,test_size = 0.2, random_state = 44,shuffle=True)
#train_x,train_y = X,Y
#print(train_x)
#print(train_y)
#print(Y_2)
Among the code -> "lgb_params = {} " you can add more parameter in it. The parameters please refer to the offical document.
Furthermore, add the 'verbose':-1 in the lgb_params can eliminate -->> WARNING "[LightGBM] [Warning] No further splits with positive gain, best gain: -inf"
lgb_params = {
'boosting_type':'gbdt',
#'objective':'binary',
'learning_rate':0.00001,
'verbose':-1 #可消除擾人的 WARNING "[LightGBM] [Warning] No further splits with positive gain, best gain: -inf"
}
# model 1
lgb_train = lgb.Dataset(X,Y)
model = lgb.train(lgb_params,lgb_train)
# model 2
lgb_train_2 = lgb.Dataset(X,Y_2)
model_2 = lgb.train(lgb_params,lgb_train_2)
## 最多只show 前10
modelA = lgb.plot_importance(model,max_num_features=5)
modelB = lgb.plot_importance(model_2,max_num_features=5)
#print(modelA)
#print(modelA)
'''
上面 modelA, modelB 2行 -> 換成下面這2行 -> 打在 Jupyter notebook 會出現圖表 (5代表為前5重要的欄位; 此專案的欄位共5行,鄉都輸出則可打max_num_features=5)
lgb.plot_importance(model,max_num_features=5)
lgb.plot_importance(model_2,max_num_features=5)
'''
pred = model.predict(test_x)
df_pred = pd.DataFrame(pred)
#df_pred
# coding: utf-8
# pylint: disable = invalid-name, C0111
import json
import lightgbm as lgb
import pandas as pd
from sklearn.metrics import mean_squared_error
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
iris = load_iris()
data=iris.data
target = iris.target
X_train,X_test,y_train,y_test =train_test_split(data,target,test_size=0.2)
# 加载你的数据
# print('Load data...')
# df_train = pd.read_csv('../regression/regression.train', header=None, sep='\t')
# df_test = pd.read_csv('../regression/regression.test', header=None, sep='\t')
#
# y_train = df_train[0].values
# y_test = df_test[0].values
# X_train = df_train.drop(0, axis=1).values
# X_test = df_test.drop(0, axis=1).values
# 创建成lgb特征的数据集格式
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
# 将参数写成字典下形式
params = {
'task': 'train',
'boosting_type': 'gbdt', # 设置提升类型
'objective': 'regression', # 目标函数
'metric': {'l2', 'auc'}, # 评估函数
'num_leaves': 31, # 叶子节点数
'learning_rate': 0.05, # 学习速率
'feature_fraction': 0.9, # 建树的特征选择比例
'bagging_fraction': 0.8, # 建树的样本采样比例
'bagging_freq': 5, # k 意味着每 k 次迭代执行bagging
'verbose': 1 # <0 显示致命的, =0 显示错误 (警告), >0 显示信息
}
print('Start training...')
# 训练 cv and train
gbm = lgb.train(params,lgb_train,num_boost_round=20,valid_sets=lgb_eval,early_stopping_rounds=5)
print('Save model...')
# 保存模型到文件
gbm.save_model('model.txt')
print('Start predicting...')
# 预测数据集
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration)
# 评估模型
print('The rmse of prediction is:', mean_squared_error(y_test, y_pred) ** 0.5)


 iThome鐵人賽
iThome鐵人賽